TCP拥塞控制
通过窗口管理,发送端与接收端能够协调彼此的发送和接收速率,避免出现超出接收端能力的丢包。但网络并非只有这一个TCP连接在使用,当数据报在发送端和接收端之间传输时,需要流转多个网络设备,这些网络设备的能力和使用情况也不同。你可以把网络设备看成是城市中的道路,数据报文就是其中的车辆,当车辆超过某一条道路的处理能力,由于数据报文并不是车辆可以提前选择别的道路,电信号只能被丢弃,于是这条道路直接将车辆扔进外太空,这种现象叫做拥塞。 但数据报文并不是现实世界的车辆,并不具备观察拥塞自动避让的能力。如何避免发生拥塞,以及发生堵塞时如何合理避让,这就是TCP的拥塞控制(Congestion Control)。
拥塞控制需要关注的几个问题:
- 拥塞控制是怎么工作的?
- 当网络出问题的时候,怎么看是不是拥塞的问题?
- 高速网络如何避免拥塞控制导致的传输效率降低?
拥塞征兆:怎么知道发生了拥塞?
在内核算法层面, 丢包、收到重复的ACK、收到SACK, 都可以认为是网络中发生了拥塞。而ECN算法通过一个扩展位协商,允许一个TCP发送端向网络报告拥塞状况,而无需检测丢包,也可以用作拥塞检测的方法。
ECN在Linux下可以通过net.ipv4.tcp_ecn与net.ipv4.tcp_ecn_fallback两个值配置。作为一个扩展,并非网络中所有的设备都支持该功能,因此并不能保证起作用。当net.ipv4.tcp_ecn=1时,TCP连接默认开启ECN,当其为2时,Linux将只对accept且开启了ECN的TCP连接启用ECN。 net.ipv4.tcp_ecn_fallback置为1,可以使TCP在尝试ECN失败时尝试不使用ECN。
大部分拥塞控制算法都是基于以上方法,如reno, cubic等。也有一些算法尝试通过检测RTT的增大来预判拥塞的发生,例如vegas, westwood等。
在日常生活中,也会经常听到说法“网络不好”,那么可以使用iperf测试TCP/UDP的网络状况:
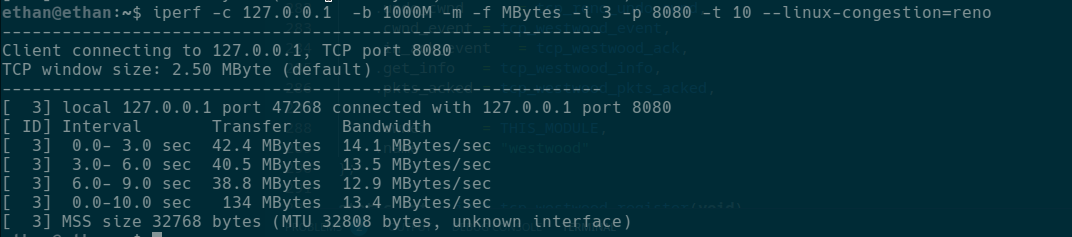
图中的TCP Server可以用go通过我写的一端简单代码运行,随便选一个公网,是不会允许随意写入的。
我们还可以通过tc来模拟网络延迟和丢包,例如下载对lo网卡增加100ms延迟,发现传输变慢了:
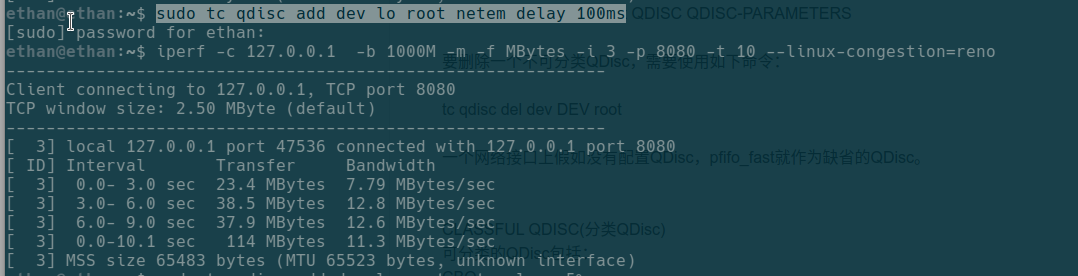
tc对lo网卡造成的负面影响可以通过sudo tc qdisc delete dev lo root消除。
更多tc的使用可以参考: linux下使用tc模拟网络延迟
拥塞窗口(Congestion Window)
在Linux上使用命令ip tcp_metrics,就会获得一个列表,代表了我们与其它主机的TCP连接相关数据。其中的rtt以及rttvar在超时重传中已经介绍过,这里出现了一个cwnd参数,即拥塞窗口(Congestion Window),它表示我们向该IP发送TCP数据报时,没有收到ACK回复的数据量不能大于10.

在TCP流量控制中,还有一个通知窗口awnd,取:
$$W=min(cwnd, awnd)$$
这样,我们对外发送但没有收到ACK的数据量不能多于W, 已经发出但还没确认的数据量大小,也叫做在外数据值(flight size),总是小于等于W.
W 不能过大或过小,我们一般希望能够接近带宽延迟积(Bandwidth-Delay Product, BDP),也被称作最佳窗口大小, 因为这时发送数据能够最大化利用带宽。
$$BDP=Bandwidth * Delay$$
慢启动
传输初始阶段,由于不清楚网络传输能力,需要缓慢探测可用传输资源,防止短时间内注入大量数据导致拥塞。这个缓慢探测的过程,就是慢启动,它主要目的是预防拥塞。
取$SMSS=min(接收方MSS, MTU)$, 初始窗口(Initial Window, IW)设置约1SMSS, 然后每次发送上次数据报的两倍,等到接收到ACK之后,再发上次的两倍,直到出现丢包停止增长。上面我们说过拥塞窗口取cwnd和awnd中的较小值,当接收方的awnd足够大时,cwnd就是决定因素。这时如果采用延时确认,TCP会直到慢启动结束才返回ACK,会导致cwnd增长较慢。
慢启动主要目的是帮助确定一个慢启动阈值(ssthresh),当达到这个阈值时,就要开始进行拥塞避免。
拥塞避免
当慢启动达到阈值时,可能有更多的传输资源,但我们不能再像慢启动时的指数增长那样一下子占用很多资源,导致其它连接出现拥塞丢包。 这时,每接收到一个ACK,这样更新cwnd:
$$cwnd_{t+1} = cwnd_{t} + SMSS *SMSS/cwnd_{t}$$
我们通常认为慢启动阶段,cwnd呈指数增长, 而拥塞避免阶段,cwnd呈线性增长.
慢启动和拥塞避免的选择
一般慢启动和拥塞避免在同一时刻只会使用一个。当cwnd < ssthresh, 使用慢启动算法;当cwnd > ssthresh,使用拥塞避免算法;当 cwnd = ssthresh,任一都可使用。慢启动阈值ssthresh并不是固定值,而是记录了上次没有丢包情况下“最好的”操作窗口估计值。
拥塞窗口校验(CWV)
拥塞窗口校验(Congestion Window Validation, CWV),这种机制主要目的是防止TCP连接由于长期空闲,之前已经较高的cwnd无法准确反映网络状况,导致网络拥塞。因此CWV机制就是在TCP停止发送一端时间后,开始衰减cwnd。但CWV在尝试衰减cwnd时,需要弄清楚TCP连接是空闲(idle,暂时没有数据需要发送)还是应用受限(application-limited,因为CPU竞争等原因,有数据需要发送但是暂时没轮上),这两种情况下,cwnd都有必要适度衰减。当TCP是空闲时,空闲一段时间之后,网络可能已经进入了严重拥堵状态,因此需要比较快的衰减。当应用受限时,虽然资源竞争对TCP的影响力不太可能有闲置那么久,但仍有必要对其做相对较慢的衰减。
Linux内核中的拥塞控制算法
拥塞控制算法的配置和选择
在较新的Linux内核中,可以在net/ipv4/Kconfig文件中看到以下内容:
config DEFAULT_TCP_CONG
string
default "bic" if DEFAULT_BIC
default "cubic" if DEFAULT_CUBIC
default "htcp" if DEFAULT_HTCP
default "hybla" if DEFAULT_HYBLA
default "vegas" if DEFAULT_VEGAS
default "westwood" if DEFAULT_WESTWOOD
default "veno" if DEFAULT_VENO
default "reno" if DEFAULT_RENO
default "dctcp" if DEFAULT_DCTCP
default "cdg" if DEFAULT_CDG
default "bbr" if DEFAULT_BBR
default "cubic"
在如今的Linux内核参数中(2.6.13开始),有三个参数可以控制拥塞控制算法:
net.ipv4.tcp_allowed_congestion_control = reno cubic
net.ipv4.tcp_available_congestion_control = reno cubic
net.ipv4.tcp_congestion_control = cubic
这表明目前系统设定可用的拥塞控制算法有 reno, cubic两种,默认为cubic。那么如何选择他们?这就需要了解这些算法的特点,来根据自己的使用场景进行设置了。
我们可以通过modprobe命令动态加载内核模块,这样就可以增加可选的拥塞控制算法了,例如我们使用modprobe tcp_highspeed:

在编写代码时,可以通过setsockopt手动设置socket使用的拥塞控制算法。对于监听连接,会从之前继承拥塞控制算法。
Linux内核中拥塞控制算法的主要组成部分
struct tcp_congestion_ops tcp_reno = {
.flags = TCP_CONG_NON_RESTRICTED,
.name = "reno",
.owner = THIS_MODULE,
.ssthresh = tcp_reno_ssthresh,
.cong_avoid = tcp_reno_cong_avoid,
.undo_cwnd = tcp_reno_undo_cwnd,
};
对于每个拥塞控制算法,都有类似上面的代码,它有点像C++的抽象类,每个算法都实现对应的部分。reno算法的拥塞参数代表了该拥塞控制算法的主要组成部分:
name字段表明算法名字ssthresh用于确定慢启动阈值cong_avoid用于拥塞避免undo_cwnd用于取消cwnd增长或衰退- 其它算法中还可能看到
init,pkts_acked等,用于处理初始化、收到ACK包等(因为有些算法是通过ACK来进行拥塞避免等操作的)
Tahoe,Reno与快速恢复
Tahoe算法是早起BSD采用的算法。连接一开始处于慢启动状态,当出现丢包时,重新将cwnd设定为初始值,重新开始慢启动。这个算法的问题是在BDP较大的链路来说,会使得TCP发送方经常重新慢启动,不能有效的利用带宽。
根据包守恒原理(数据包从发送端到接收端,总会以某种形式存在于某个地方,当发送方和接收方达成平衡,并将链路塞满时,就能达到理想的传输状态),只要能够收到ACK(包括重传ACK),就有可能传输新的数据包。因此,Reno算法中加入了快速恢复机制, 在恢复阶段,每收到一个ACK,cwnd就能临时增长1 SMSS, 因此拥塞窗口会在一段时间内急速增长,直到接收一个好的ACK。不重复的ACK(好的)表明TCP结束恢复阶段,拥塞已经减少到之前状态。
Reno算法在Linux内核中总是一个可用的选择,也是作为一个“TCP标准”实现的。Reno的特点是能够比较公平的分配带宽,也能够比较好的利用带宽。
标准TCP
在RFC5681中描述了一个基础的方法,被许多基础的TCP实现所使用。
慢启动阶段, ssthresh取较大值(>=awnd),当收到一个好的ACK时,执行以下更新:
$$cwnd += SMSS (若cwnd<ssthresh,执行慢启动)$$ $$cwnd += SMSS *SMSS/cwnd (若cwnd>ssthresh,执行拥塞避免)$$
当收到三次重复ACK,或其它表明需要重传的信号时:
ssthresh更新为大于以下等式的值:
$$ssthresh = max(flightSize/2, 2 * SMSS)$$
-
启用快速重传算法,设置 $cwnd=(ssthresh+3*SMSS)$
-
每接收一个重复
ACK,$cwnd+=1SMSS$ -
当接收到一个好的
ACK, $cwnd=ssthresh$
标准TCP每接收到一个好的ACK,cwnd增加1/cwnd,每出现一次丢包,cwnd减半,这被称为和式增加/积式减少(Additive Increase/Multiplicative Decrease, AIMD)拥塞控制。通过将1/cwnd替换为a, 1/2替换为b,得到AIMD一般化等式:
$$cwnd_{t+1}=cwnd_{t}+a/cwnd_{t}$$
$$cwnd_{t+1}=cwnd_{t}-b*cwnd_{t}$$
设p为丢包率[0, 0.1],故每个RTT内发包个数为:
$$T=\frac{ \sqrt{ \frac{a(2-b)}{2b} } }{\sqrt{p}}$$
对于标准TCP, a=1, b=0.5, 故而可以简化为 $T=1.2/\sqrt{p}$
高速网络环境下的HSTCP(Highspeed TCP)
在高速网络环境下,传统的TCP使用AIMD拥塞控制,面临以下问题:
- 在线性增加阶段,高速网络下
cwnd很容易变得很大,导致到达临界点时,下一次增长立即导致积式减少,不能探知理想的边界。 - 在积式减少阶段,高速网络下的
cwnd马上衰减成一个较小的值,严重降低宽带利用率。
为了解决上述问题,RFC3649定义了一种高速环境下能够充分利用带宽,低速环境下与标准TCP一致的算法。
HSTCP修改了慢启动阶段,称为“受限的慢启动”,引入新的参数max_ssthresh,当 cwnd<=max_ssthresh, 增长方式与传统TCP相同。当超过这个阈值,cwnd每次只能增长max_ssthresh/2个SMSS,规避以单斜率线性增长导致无法探知正确边界的问题。
另外,通过之前的每隔RTT发包个数计算公式,在不同的丢包率下,通过调整a和b的值,可以有效的增大发包效率。HSTCP通过设定不同的比率,优化了其发送效率。在丢包率较大时或窗口较低时,HSTCP与传统TCP发送效率基本一致。
Linux内核中,HSTCP的配置算法名为highspeed,代码实现在net/ipv4/tcp_highspeed.c中。
HSTCP在拥有大BDP的网络中,能够让低RTT的TCP连接得到更高的带宽,当有多个不同RTT的连接竞争时,高RTT的连接将会遭到不公平的对待。
二进制增长拥塞控制:BIC和CUBIC
上面提到了HSTCP的不公平性, 而BIC和CUBIC则尝试在有效利用高速网络的时候同时兼顾公平性。最开始是BIC,在此基础上,Linux内核现在默认使用的是CUBIC。
BIC
BIC的核心思想是在和式增加上增加了BI,即二分搜索增加(Binary Increase),思路是取无丢包的窗口为A,,取有丢包的窗口为B,然后找到中间值看是否丢包,如果发生丢包,则取之为B,反之则为A,以此类推,直到两者之间的差值低于临界值$S_{min}$时停止,就能在对数时间内找到合适的窗口。这种方式越接近临界值,增长越慢,容易找到饱和点。但是,在一个RTT内突然将cwnd提升到中值,可能会导致严重的拥塞,因此当最大值与最小值之间的差值大于临界值$S_{max}$时,就不再使用二分搜索直接取中值,而是采用和式增加,每次增加不超过$S_{max}$。
CUBIC
BIC使用固定的临界值来决定何时使用BI,何时使用AI,不能很好的自动适应不同的网络环境,另外也存在某些情况下增长过快的问题。在BIC基础上,CUBIC通过一个高阶多项式函数来控制窗口的增大:
$$W(t)=C(t-K)^{3}+W_{max}$$
在表达式中,t是距离最近的一次窗口减小所经过的时间,以秒为单位, W(t)代表时刻t的窗口大小,C是一个常量(默认为0.4)。$W_{max}$是最后一次调整前的窗口大小, K是在没有丢包的情况下窗口从W增长到$W_{max}$所用的时间。
CUBIC还增加了“TCP友好性”功能,当发现CUBIC的窗口增长不如标准TCP时,可以采用标准TCP的,这样就实现了在低速网络环境下的性能优化。
基于延迟的拥塞控制算法
之前的拥塞控制算法都是利用丢包,SACK,重复ACK等探测拥塞,从而启动拥塞避免过程。当拥塞即将发生时,RTT也会逐渐增大,因此有一类拥塞算法,利用RTT增长趋势来检测拥塞并生效。
Vegas算法
在拥塞避免阶段,Vegas算法测量每个RTT所传输的数据量,并将该数据除以网络中观察到的最小延迟时间,得到$v=T/RTT_{min}$。算法维护两个阈值$\alpha$和$\beta$,其中$\alpha<\beta$。当$v<\alpha$,增大拥塞窗口;当$v>\beta$,减小拥塞窗口。若$\alpha\le v \le \beta$,窗口保持不变。其中拥塞窗口的改变是现行的,即和式增加/和式减少(Additive Increase/Additive Decrease, AIAD)的拥塞控制策略。
由于Vegas是通过RTT来评估是否需要拥塞避免,当发送端与接收端往返的链路不同,而ACK的链路发生拥塞时,Vegas会误判认为需要减少发送端的数据发送,过度降低发送窗口。
Vegas与其它的Vegas TCP链接共用链路时,是平等的。但是与标准TCP共用链路时,由于标准TCP的目标是占满等待队列,而Vegas则是尝试通过预判来使队列相对空闲,这时Vegas将会自动降低发送速率,导致在竞争中处于劣势。
Vegas目前在Linux内核中设置$\alpha=2$, $\beta=4$且不可动态调整,需要手动加载模块tcp_vegas后,修改net.ipv4.tcp_congestion_control来启用它。
Westwood算法
Westwood是基于延迟在New Reno算法基础上进行了改进,从而实现对大带宽延迟积链路的处理。当发生丢包时,Westwood不会直接将cwnd减半,而是根据$RTT_{min}$计算出一个估算BDP,然后将ssthresh值更新成该值。在慢启动阶段,它是呈指数增加的。
westwood 也可以通过类似vegas的方式在Linux中启用。