Runc容器运行过程及容器逃逸原理
在每一个Kubernetes节点中,运行着kubelet,负责为Pod创建销毁容器,kubelet预定义了API接口,通过GRPC从指定的位置调用特定的API进行相关操作。而这些CRI的实现者,如cri-o, containerd等,通过调用runc创建出容器。runc功能相对单一,即针对特定的配置,构建出容器运行指定进程,它不能直接用来构建镜像,kubernetes依赖的如cri-o这类CRI,在runc基础上增加了通过API管理镜像,容器等功能。
Kubelet,Cri-O,runc,Linux大致层级示意图如下:
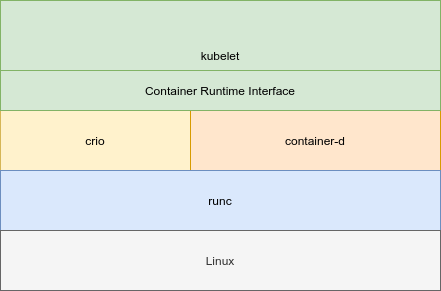
在Kubernetes源码中,可以在pkg/kubelet/cri目录下找到相关代码,其中remote目录包含了常见的如镜像拉取,容器创建等操作,streaming目录中包含了一些需要TCP流的操作,如attach,port-forward等。
构建并使用runc运行一个容器
构建
runc的源码可以下载并通过make命令构建:
git clone https://github.com/opencontainers/runc.git
cd runc
make
runc是一个Go程序,使用CGO调用了一些外部库。构建除了需要安装go之外,可能需要额外安装如pkgconfig, libseccomp-dev, libseccomp等包,视具体错误排查。
运行容器
runc并不负责从镜像等上下文直接创建容器,因此需要从docker等更高级的运行时直接导出CRI,会更容易一些。
mkdir /mycontainer
cd /mycontainer
# create the rootfs directory
mkdir rootfs
# export busybox via Docker into the rootfs directory
docker export $(docker create busybox) | tar -C rootfs -xvf -
然后使用构建好的runc创建出容器运行的具体配置config.json:
runc spec
切换到root,然后运行:
runc run <container-id>
或者将run命令拆解,分成多步运行:
runc create <container-id>
runc list # 列出创建状态的容器
runc start <container-id>
runc list
runc delete <container-id>
运行分析
通过ps axef命令,打印出所有进程及其层级关系,发现我们之前运行的容器进程关系如图:
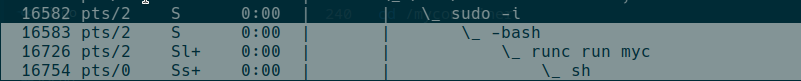
表面上看,在通过runc run <container-id>之后,进程创建了一个子进程sh,也就是我们进入容器后指定运行的第一个程序。
容器隔离机制
Linux通过namespace将不同的资源隔离,就像一个沙箱一样。被隔离到某个namespace中的内容,无法访问到其它namespace的内容。可以通过unshare或clone设置标志位来将进程放入新的命名空间。
- PID Namespace
标志位: CLONE_NEWPID
文档: man pid_namespaces
即进程命名空间,在一个隔离的空间中,PID从1开始,相同PID与主机PID不构成冲突。类似主机的init进程,PID为1的进程被终止时,该命名空间下的所有进程都会收到SIGKILL信号从而被终止。正因如此,一个容器的初始化进程只能是一个,而且终止后容器也就被停止了。
在不同的PID命名空间,进程互相看不到对方,不能通过PID找到对方,/proc目录下也只能看到自己命名空间中的进程。但是一个父进程fork出的子进程可以通过set_ns放入子命名空间,在父进程的命名空间,仍然可以看到这个子进程,只是PID不一样。进程可以被挪到子命名空间,但不能被反向挪回更高级的命名空间。
- User Namespace
标志位: CLONE_NEWUSER
文档: man user_namespaces
用户命名空间,主要隔离的是安全相关的id和属性,尤其是用户id和用户组id,root目录,密钥,以及各种进程的能力(capabilities)。
- Network Namespace
标志位: CLONE_NEWNET
文档: man network_namespaces
网络命名空间,隔离出全新的网络设备、IPv4、IPv6协议栈,路由表,iptables规则,以及sockets,端口号。隔离后,命名空间下的/proc/net以及/sys/net也会不同于上级命名空间。
一对veth网络设备可以实现跨命名空间的通信,也可以桥接到主机物理设备上。
- UTS Namespace
标志位: CLONE_NEWUTS
隔离hostname以及NIS domain name,两个都是主机对自己的网络标识,在容器中可以重新定义。
- Cgroup Namespace
标志位: CLONE_NEWCGROUP
文档: man cgroup_namespaces
Cgroup Namespace隔离出了新的cgroup分组,可以通过/proc/[PID]/cgroup获得进程的cgroup相关情况。Cgroup是Control group的缩写,不同的cgroup通过树状结构组织在一起,每个节点上挂载着不同的控制器(controllers),可以通过他们控制cpu, memory, bulkio等资源的使用,也可以获得cpu等资源的使用情况,或者通过freezer将进程暂时冻结或恢复。
- IPC Namespace
标志位: CLONE_NEWIPC
隔离了System V常用的IPC通信手段,如信号量(semaphore),共享内存,消息队列等。
- Mount Namespace
标志位: CLONE_NEWNS
挂载文件系统的隔离,但是一部分文件系统也可以通过共享跨命名空间共享。通过cat /proc/self/mountinfo可以获得挂载信息,带有shared标志的就是共享出来的部分。
runc容器初始化流程
runc目前初始化大致流程如下图所示,其中一些步骤经过了简化:
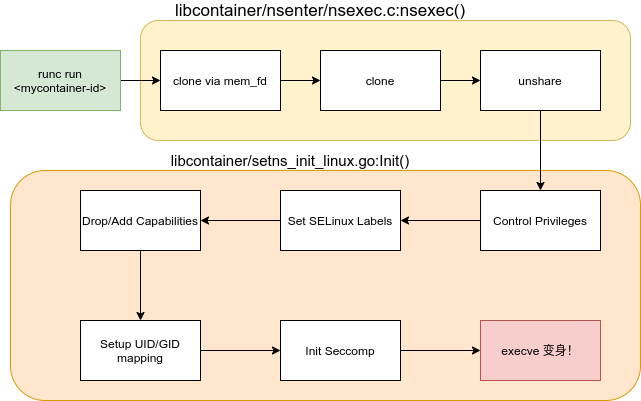
通过在init.go中隐式的导入包: import _ "github.com/opencontainers/runc/libcontainer/nsenter", runc在初始化阶段就完成了clone/unshare过程,创建出子进程,并将其通过setns放入新的命名空间:
/*libcontainer/nsenter/nsexec.c:join_namespaces(char*)*/
for (i = 0; i < num; i++) {
struct namespace_t ns = namespaces[i];
if (setns(ns.fd, ns.ns) < 0)
bail("failed to setns to %s", ns.path);
close(ns.fd);
}
一般来说,只要通过clone/share+setns+execve就可以完成容器的基本运行过程,在发现漏洞[CVE-2019-5736]之后,runc加入了一段重要代码ensure_cloned_binary,确保当前runc是通过memfd在内存中克隆出来并重新运行的。
容器逃逸
“特权"容器
“特权"在runc及基于containerd的docker中, 对应选项是--privileged,在K8S中对应的是pod.Spec.privileged: true,但它的特权实际指的是User Namespace中的Capabilities,即启动容器时用户的Capabilities将会全部被保持,不会为了构建沙箱而扔掉权限,这样容器就可以执行各种特权操作,例如挂载文件系统,改写主机iptables,改写主机Ipvs等。因此对于像kube-proxy这类需要改写主机网络的组件,一些容器,可能还会需要访问特定的蓝牙设备或GPU等,它们要正常工作,就必须拥有特权。
但这种特权实际已经是“超级特权”了,必须经过谨慎的权衡使用,一般不会被普通用户滥用。容器面临的权限安全问题,更多的是来自UID/GID映射。
通过User Namespace,我们可以将主机/上级namespace中的一个普通用户映射成子namespace中的一个特权用户root或者其它,反之则不行。但是Linux的权限系统是通过UID/GID来辨认用户的,当一个容器中的UID 0用户在主机中被映射成UID 0时,那么容器中的进程如果能够访问主机上的文件,它实际等同于root(UID=0),这时候就有了逃逸的机会。所谓容器逃逸,就是容器中的进程通过某种方式改写主机环境,从容器这个平行世界中“逃脱”,改变主世界。在容器中它可能只是个“村长”,但由于它的UID与外面的“国王”相等,一旦逃逸发生,它就等同于拥有“国王”权限,可以对外发布更高权限的命令。
对此,我们可以在主世界创建一个“村长”(UID=65535),然后将有限的领土“村级行政区”划分给他,然后映射到子命名空间中做“国王”(root,UID=65535),这样即使容器中的国王逃出来,它依然只能治理之前划分给它的那一小块“村级行政区“。
更多关于“特权”容器的讨论可以参考LXC作者的这篇博客。
CVE-2019-5736: 改写runc容器逃逸
在2019年初,爆发了一个容器严重漏洞,运行docker的容器环境,普通用户可以通过特殊构建的镜像,运行后改写主机上的runc,从而进一步进行入侵操作。
当一个进程运行时,它自己可以通过/proc/self/exe得到指向自己的链接,也可以进一步在/proc目录下找到自己的fd。一个恶意构建的镜像可以将自己的入口改成/proc/self/exe,由于容器入口需要通过runc来clone+execve启动,这样就使得一个普通的用户容器,访问并执行了主机上的runc。
之前编译runc的步骤中,我们也已经知道了,runc使用了CGO来调用libc/libseccomp的代码,通过ldd命令可以看到runc的外部依赖库:

在之前的runc容器初始化流程中,我们直到当容器开始执行我们的程序时,已经进入了新的namespace,这时程序如果需要外部依赖什么文件,一定会从容器内寻找,这时我们可以通过修改容器的LD_LIBRARY环境变量,迫使runc优先使用改造过的.so文件,而这个.so的作用,就是改写/proc/self/exe指向的文件,即主机上的runc。
在这个漏洞中,我们可以看到它需要满足几个条件:
- 容器能够通过入口
/proc/self/exe指向主机中的runc - 容器允许用户自行任意指定,将其中的恶意代码伪装成普通文件
- 容器中的用户UID在主机中的映射UID同样具有较高权限,否则即使runc被暴露,也会因为容器中用户权限不足而无法访问
runc最终的漏洞修复手段: 增加了一个ensure_cloned_binary阶段,通过在内存中只读的复制自己并clone,避免了/proc/self/exe指向主机runc的问题。
CVE-2019-14271: 通过docker-cp容器逃逸
这个漏洞是指当运行docker的环境中调用docker cp时,如果访问的是一个恶意容器,容器中的用户就可以在主机中运行任意代码。
docker cp是通过chroot的方式,切换到容器所在主机文件目录,然后从那里复制文件。这个chroot是docker自己实现的,需要依赖nsswitch相关动态库,这时可以通过在容器中替换这些动态库,从而实现借docker cp的高级权限,运行恶意代码的目的。
官方的修复是让chroot在切换成容器目录之前就提前执行一次dns lookup,从而调用cgo,总体看上去还是稍微有点魔幻的: https://github.com/moby/moby/pull/39612/files
func init() {
// initialize nss libraries in Glibc so that the dynamic libraries are loaded in the host
// environment not in the chroot from untrusted files.
_, _ = user.Lookup("docker")
_, _ = net.LookupHost("localhost")
}
小结
从上面两个逃逸漏洞来看,仍然没有摆脱“特权用户运行恶意代码”的范畴。一些CRI如Cri-O,可以通过修改/etc/crio/crio.conf中的uid_mappings及gid_mappings修改映射,从而避免容器逃逸后容器中的进程获取主机上的文件访问权限。这样做会有一些额外负担,就是如HostPath这类挂载,需要确保主机上这部分文件也能够被指定UID访问。
另外通过扫描镜像,避免恶意镜像也可以起到一定作用。对于镜像准入需要采取一定的手段。
K8S和docker/crio的特权模式一定慎用,可以把它跟root等同审慎对待,绝对不能开放给普通用户。
关注容器生态安全漏洞,及时发现预警,避免修复不及时造成损失。